Paper Accepted at Findings of ACL 2025
Papers
Me, Alessio Miaschi, Cristiano Ciaccio and Felice Dell’Orletta from the ItaliaNLP Lab of the Institute for Computational Linguistics of the CNR published a paper with collegues from the Institute of Information Science and Technologies of the CNR Andrea Pedrotti, Giovanni Puccetti e Andrea Esuli. Our fruitful collaboration yielded a beautiful work on Machine Generated Text Detection that has been accepted at the Findings of ACL 2025. You can find the pre-print here, the code here, and the dataset here.
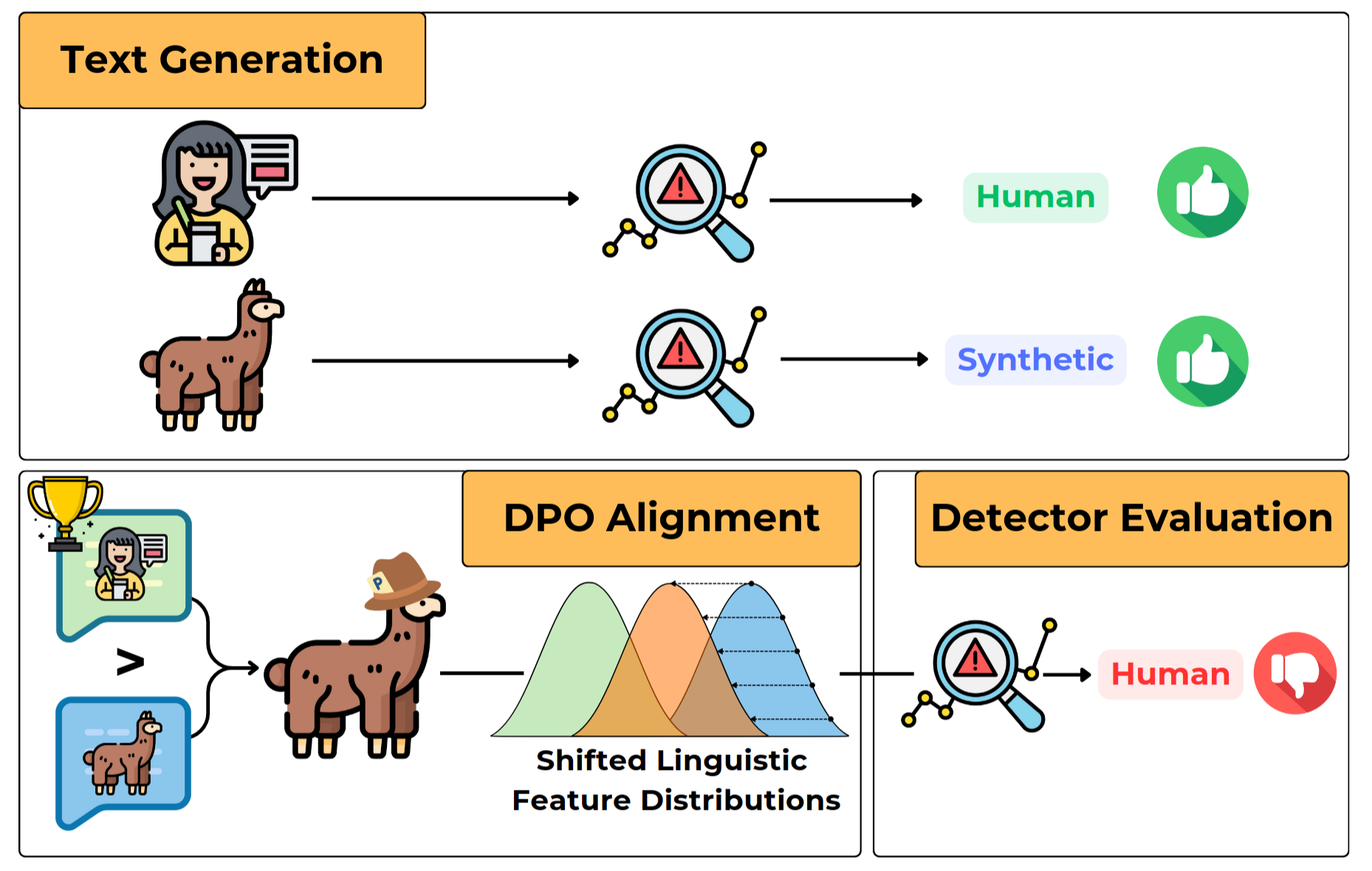
The paper focuses on Machine Generated Text Detection, and, in particular, how easy it is to fool. We show that by using Direct Preference Optimization (DPO) on a Preference Dataset constructed with couples of Human Written Text (HWT) and Machine-Generated Text (MGT), we can shift an LLM writing style towards HWT, making predicting whether a text is HWT or MGT harder (up to 60% performance drop) for state-of-the-art Machine-Generated Text Dectors.
We tested on two domains (News and Abstracts), with two families of models (Llama and Gemma) on 6 different detectors:
- Mage
- Radar
- LLM-DetectAIve
- Binoculars
- Two domain-specific detectors trained by us: a Linear-SVM and a RoBERTa.
We also checked whether our DPO fine-tuning made it easier for humans to detect the text, but their (terrible) performance in detecting MGT remained the same (around 50%, the same as bling guessing) before and after the DPO alignment.
We believe that the technique works because most detectors rely on shallow stylistic cues: word length, punctuation patterns, and sentence structure. Aligning LLMs to human style shifts the model’s writing style towards humans, and Detectors can’t keep up.
To check this, we looked at the linguistic profiling of the texts before and after DPO alignment. What we find is that MGT is significantly different, from a linguistic feature distribution point-of-view from HWT. We also find that after the DPO alignment, this difference in distribution starts to diminish, especially in the case of one of the runs we made called “DPO-ling”.
In this variant, we selected the text for the DPO alignment in a linguistically motivated way. We trained an SVM using the linguistic feature of the two classes of text and looked at which linguistic feature had the highest absolute coefficient for the SVM. We then selected the couples of MGT and HWT that maximized the differences in those linguistic feature values, aiming to find the most “representative” couples of the difference in writing style between HWT and MGT.
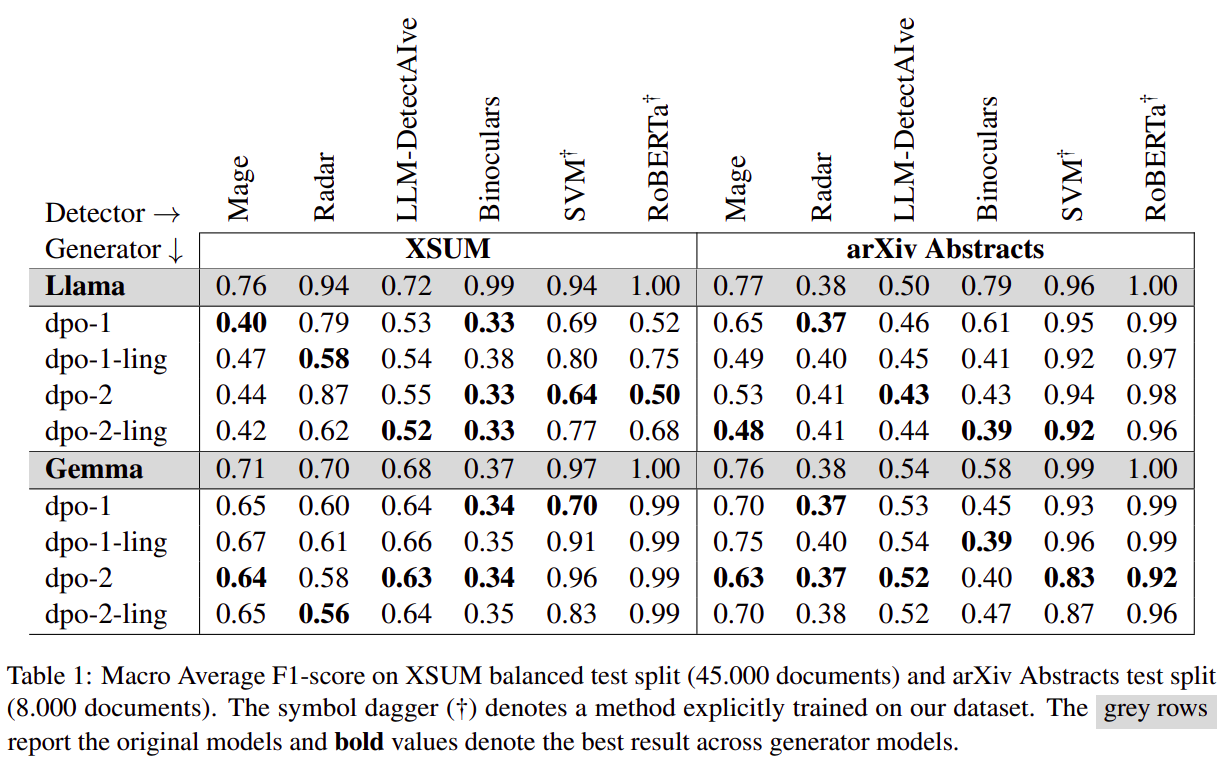
We found that DPO-ling had slightly worse performance in dropping MGT detector accuracy, but aligned the MGT distribution much better to HWT in the selected features. We believe that the better performance of the random approach may be because choosing pairs at random shifts a broader range of linguistic features, even if slightly. However, it is notable to say that the most robust detector, Radar, received the highest performance drop when evaluating the DPO-ling MGTs.
Our works shed light on the fragility of Machine-Generated Text Detection system, and urges for the creation of more reliable and robust technique. To that end, we released code and the DPO training dataset with the hope that they might be helpful in creating the next generation of MGT detectors.